

Notice
Recent Posts
Recent Comments
Link
헬창 개발자
논문 리뷰: Phi-4 Technical Report 본문
✅개요
- Phi-4 모델: 14억 파라미터의 언어 모델로, 데이터 품질에 중점을 둔 새로운 학습 방식을 적용.
- 기존 Phi-3 모델의 구조를 기반으로 개발되었으나, 합성 데이터의 활용 및 사후 학습(post-training) 혁신을 통해 성능을 크게 개선.
- 주요 목표: 추론 및 문제 해결 능력을 강화한 모델 제공.
- phi-4의 개발은 세 가지 핵심 기둥에 의해 진행됨.
- 사전 훈련 및 중간 훈련을 위한 합성 데이터
- 고품질 유기 데이터의 큐레이션 및 필터링
- SFT 데이터 세트의 새로운 개량된 버전과 핵심 토큰 검색을 기반으로 DPO 쌍을 생성하는 새로운 기술을 개발
💡정리

- 비교 대상
Phi-4, Phi-3, GPT-4o, GPT-4o-mini, Qwen 2.5, Llama-3.3 - 결과
Phi-4는 MATH(80.4), GPQA(56.1), HumanEval(82.6) 등 여러 벤치마크에서 뛰어난 성능을 보임.- 예: GPQA(대학원 수준 STEM 질문)에서 GPT-4o보다 높은 점수.
- 코드 평가(HumanEval, HumanEval+)에서도 Llama-3.3 같은 대규모 모델보다 우수
🪜phi-4 학습 단계
단계주요 목표데이터
| Pretraining | 일반적인 언어 이해와 지식 학습 | 웹 데이터, 자연 데이터 (filtered web data) |
| Midtraining | 특정 도메인/작업에 맞춤화 및 컨텍스트 길이 확장 | 긴 문맥 데이터, 합성 데이터, 도메인 특화 데이터 |
| Post-training | 사용자 선호도 반영 및 안전성 강화 | Fine-tuned 데이터 (DPO 데이터 포함) |
📂Dataset
합성 데이터의 활용
- 목적:
- 학습 효율성을 높이고, 모델이 더 정교한 추론과 문제 해결 능력을 학습할 수 있도록 지원.
- 합성 데이터가 학습 중 불필요한 잡음을 제거하고, 모델이 유의미한 패턴을 학습하도록 "스푼피딩(spoonfeeding)" 방식으로 설계.
- 합성 데이터 생성 기술:
- Multi-Agent Prompting: 여러 AI 모델이 협력해 데이터를 생성.
- Self-revision: 모델이 스스로 데이터를 검토하고 수정하며, 논리와 정확성을 개선.
- Instruction Reversal: 코딩과 같은 작업에서 문제를 역으로 재구성하여 새로운 데이터 생성. 코드를 보고 문제 설명을 만들어내는 방식.
- Chain of Thought: 단계별 추론 과정을 모델에 학습시키기 위해 설계된 데이터.
🪄pretraining
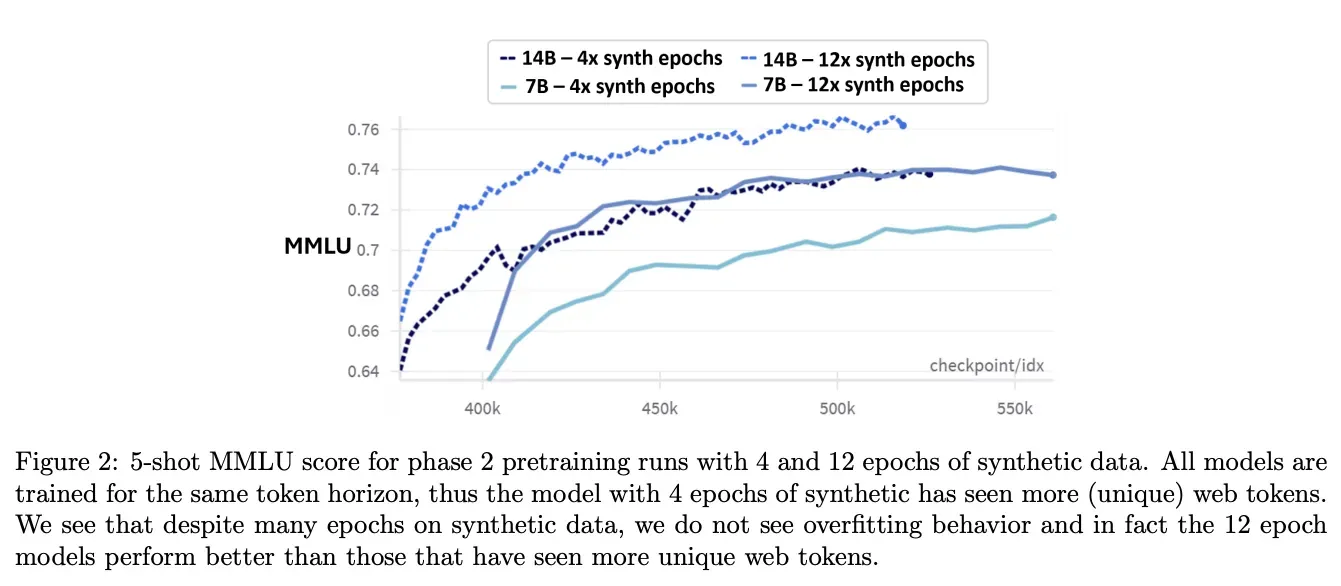
- MMLU: Phi-4는 Phi-3에 비해 3~10% 성능 향상.
- GSM8k(수학 문제): Phi-4의 성능이 8.4% 증가.
- 긴 컨텍스트 길이를 활용한 학습 덕분에 더 나은 추론 성과를 보임.
- 같은 데이터에 대해 반복 학습(4 vs. 12 epoch)을 수행한 경우, 더 많은 반복이 성능 향상에 기여.
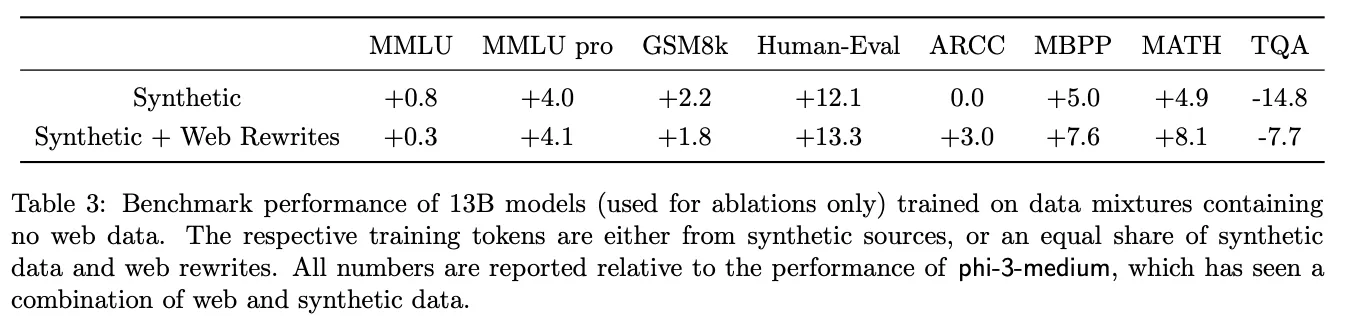
합성 데이터가 많은 경우, 웹 데이터를 사용하는 것보다 학습 성능이 더 우수. - 의미 : 합성 데이터가 반복될수록 추론 성능이 향상됨.
- TQA(지식 중심 질문): 웹 데이터가 더 효과적일 수 있지만, 합성 데이터의 이점이 크다고 평가.
🪄 Midtraining
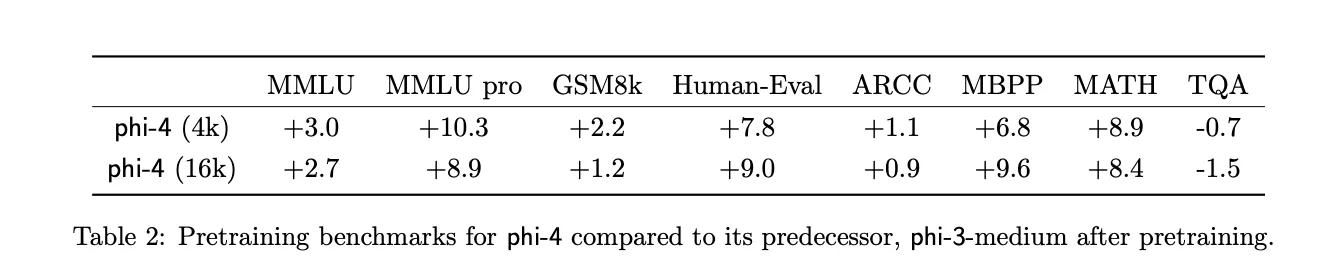
- 문맥 길이를 기존 4K에서 16K로 확장.
- 긴 문맥 작업에서 성능을 향상시키기 위해 긴 문맥 데이터를 추가적으로 생성 및 활용.
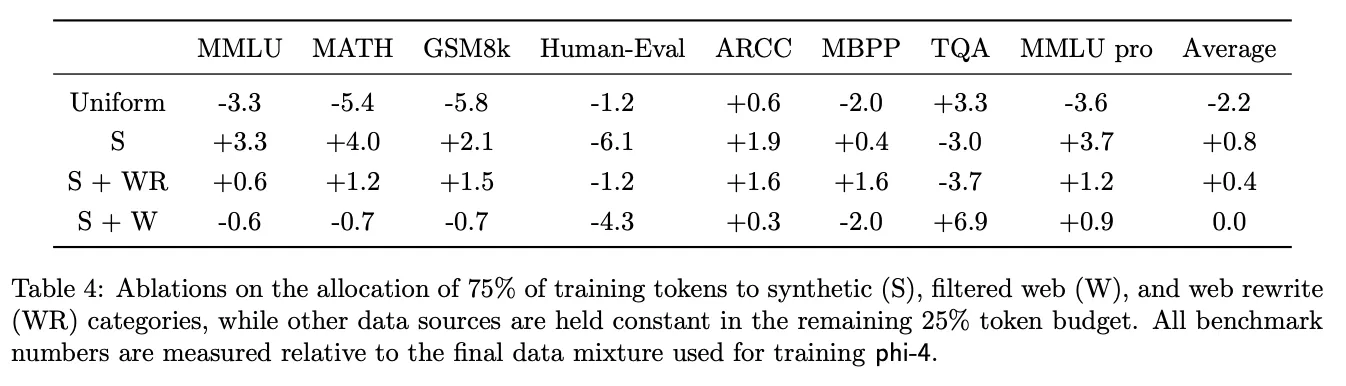
- Synthetic(S), Web(W), Web Rewrite(WR) 데이터의 비중.
- Synthetic 데이터를 많이 사용할수록 MMLU, MATH 등 추론 중심 작업에서 성능이 더 좋음.
- Web 데이터는 TQA와 같은 지식 기반 작업에서 효과
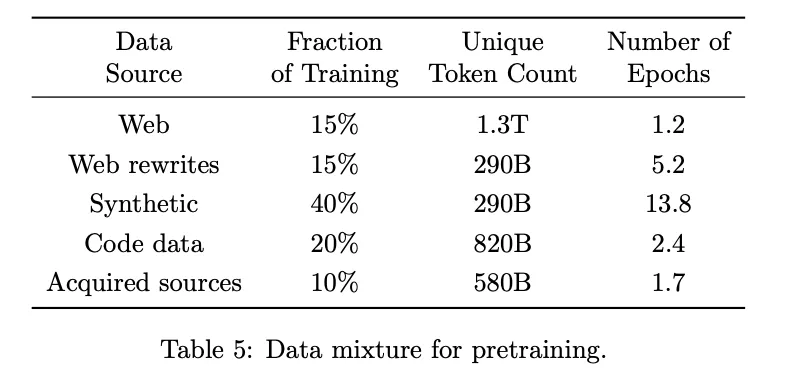
- 구성 비율:
- Synthetic: 40% (290B 토큰, 13.8 epoch)
- Web + Web Rewrite: 30%
- Code Data: 20%
- Acquired Sources: 10% (Academic, Books 등)
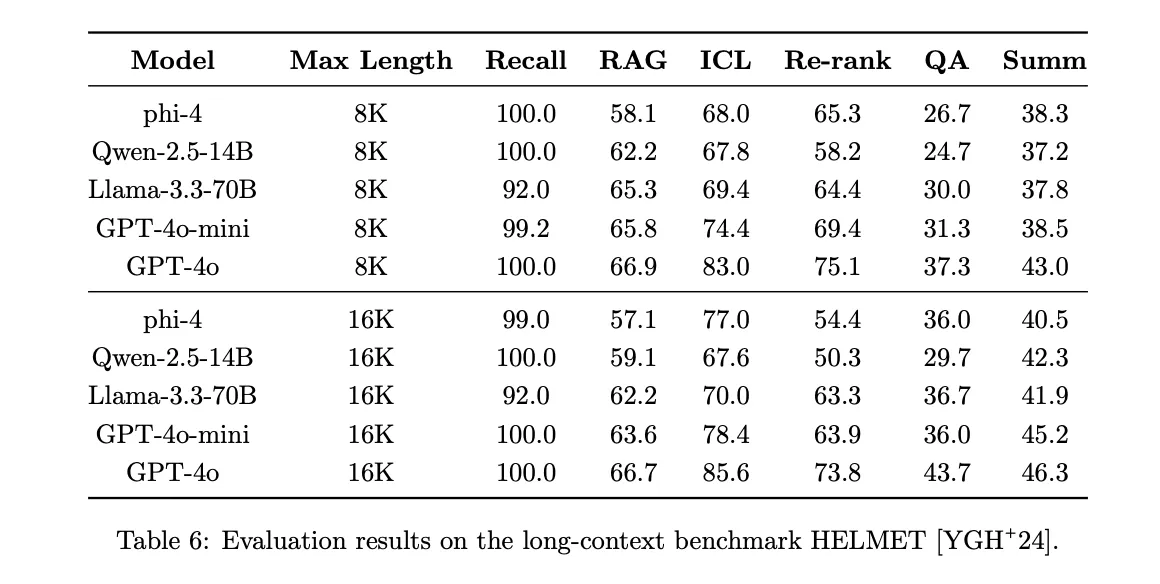
- 평가 항목: Recall, RAG, QA, Summarization 등.
- 결과: Phi-4는 긴 문맥(16K 컨텍스트)에서 대부분의 모델에 비견되는 성능을 발휘.
🪄post training
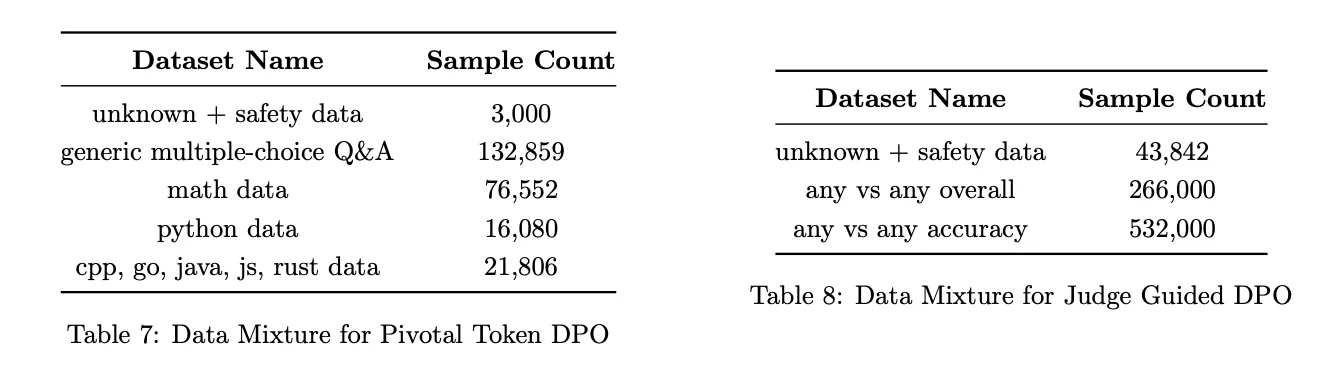
- 표 7: 첫 번째 DPO 단계(Pivotal Token DPO) 데이터.
- 주요 항목: 수학 데이터(76,552), Python 코드(16,080).
- 표 8: 두 번째 DPO 단계(Judge-Guided DPO) 데이터.
- 데이터 총합: 약 850,000 샘플.
- 안전성 및 정확성 향상을 위해 GPT-4o 기반 판단 추가
✅DPO 과정
DPO는 두 단계로 이루어지며, 각 단계에서 데이터 쌍(pairs of desired and undesired outputs)을 활용
(1) 첫 번째 단계: Pivotal Token Search (PTS) 기반 DPO
- 기법:
- Pivotal Token Search (PTS)를 사용하여 중요 토큰(pivotal tokens)을 식별
- PTS를 통해 긍정적인 응답과 부정적인 응답의 데이터 쌍을 생성하여 학습 데이터로 사용
- 효과:
- 수학, 코딩, 그리고 복잡한 추론 작업에서 모델의 성능을 향상 시킴
(2) 두 번째 단계: Judge-Guided DPO
- 데이터 생성:
- 약 85만 개의 데이터 쌍(850k pairs)을 생성
- 프롬프트는 공개된 instruction tuning datasets 및 안전성(Responsible AI, RAI) 관련 프롬프트에서 수집
- 응답 생성 및 평가:
- 각 프롬프트에 대해 GPT-4o, GPT-4t, Phi-4 모델에서 생성된 응답을 수집
- 생성된 응답 쌍에서 GPT-4o를 심판(judge)으로 사용하여 다음 기준으로 긍정적/부정적 응답을 분류:
- 정확성(Accuracy).
- 스타일(Style).
- 세부성(Detail).
- 평균 점수 또는 정확성 기준으로 긍정 응답을 선택
Pivotal Token의 개념
- 일부 토큰은 성공 확률의 급격한 변화를 유발하며, 이러한 토큰을 Pivotal Token이라고 함.
- 모델이 프롬프트에 대해 응답을 생성할 때, 각 토큰은p(success∣t1,...,ti)위 조건부 성공 확률 에 기여 함
- 예를 들어, 수학 문제 풀이 과정에서 중요한 단어(예: "곱셈" 또는 "부호")가 결과의 성공과 실패를 결정짓는 역할을 할 수 있음.
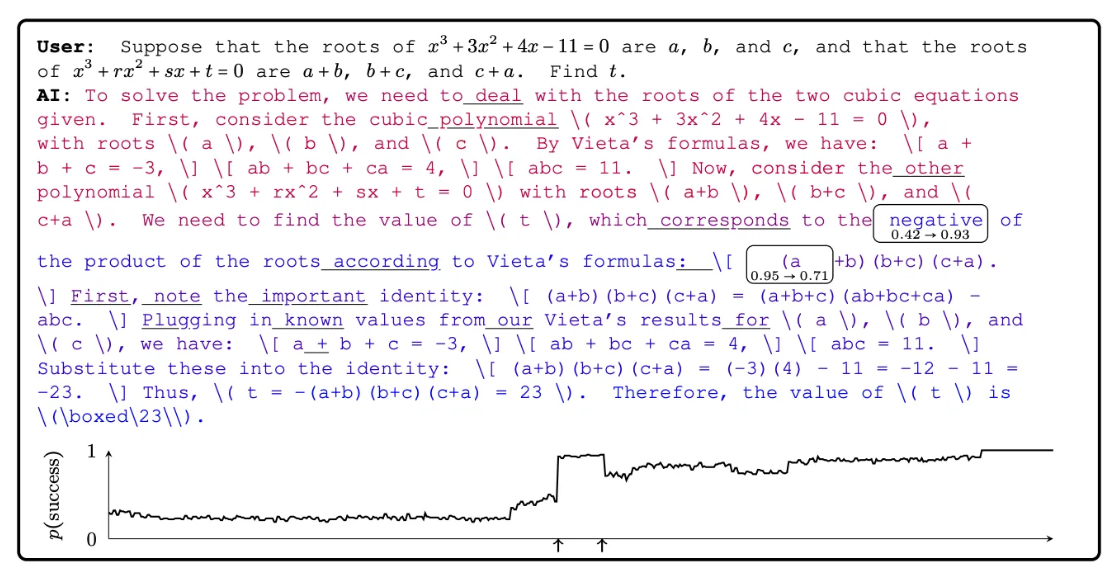
- 특정 토큰(예: "negative")이 결과에 중요한 영향을 미침.
- 추론 성공 확률에 크게 기여하는 토큰을 학습 대상으로 설정.
주어진 프롬프트에 대한 토큰별 응답을 생성하는 생성 모델을 고려함. 모델 응답에 해당하는 생성된 각 토큰에 대해 해당 토큰을 기준으로 모델의 답변이 옳을 조건부 확률과 해당 토큰에 대한 이 확률의 증가분(즉, 해당 토큰을 생성하기 전과 후에 옳을 확률의 차이)을 고려

피봇탈 토큰 알고리즘
(1) Subdivide 함수 -> 재귀 탐색 시작
(2) Pivotal Token 탐지 -> 변화량이 𝑝gap이상이면 피봇탈 토큰 식별
(3) 반복 및 출력
(4) t-acc, t-rej 선별

PTS 알고리즘의 데이터 생성 흐름
- 성공 확률 분석:
- 각 토큰이 응답의 성공 확률에 미치는 영향을 계산.
- 성공 확률이 pgap(임계값) 이상 변화하는 토큰을 탐지.
- Good/Bad 응답 분류:
- Good 응답: 성공 확률을 높이는 피보탈 토큰 포함.
- Bad 응답: 성공 확률을 낮추거나 무관한 토큰 포함.
- 학습 데이터 생성:
- 탐지된 피보탈 토큰을 기반으로 긍정/부정 학습 데이터 쌍을 생성.
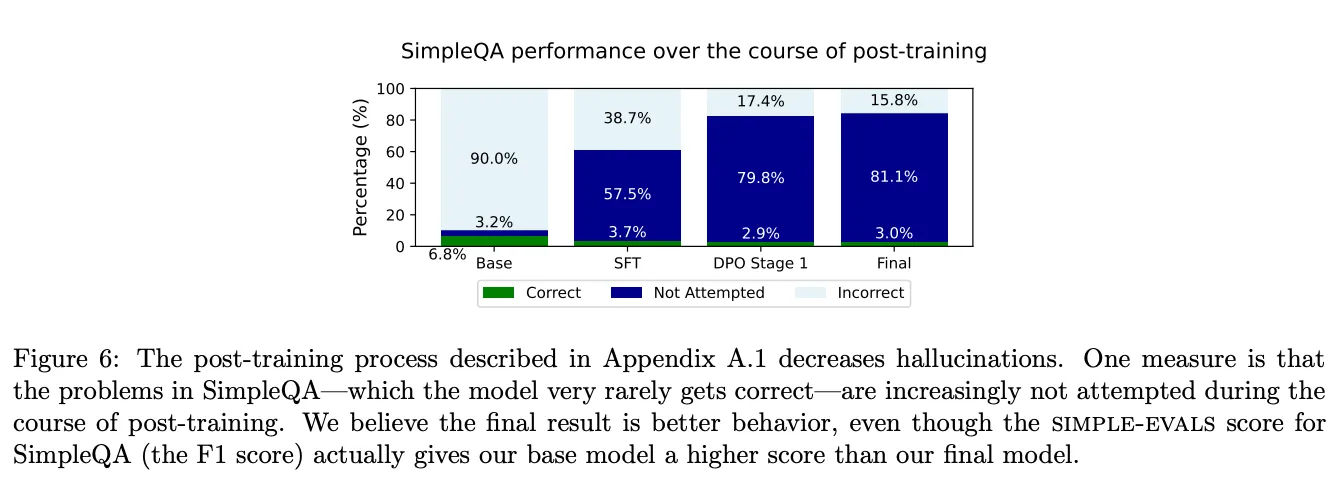
- 정답률(Correct): 질문에 대해 정확히 답변한 비율.
- 비응답률(Not attempted): 모델이 답변을 시도하지 않은 비율.
- 오답률(Incorrect): 질문에 대해 잘못된 답변을 생성한 비율.
사후 학습 과정에서 잘못된 추론이 감소하고, 모델이 답변을 포기(not attempted)하는 비율이 증가.
더 나은 사용자 경험을 위해 고도화된 학습 전략이 반영됨.
- Base SFT:
- 정답 비율: 약 6.8%.
- 모델이 단순한 질문에도 잘못된 응답(환각)을 자주 생성.
- 오답 비율: 대부분의 응답이 잘못된 답변으로 구성.
- 정답 비율: 약 6.8%.
- DPO 1단계:
- 정답 비율 증가: 약 57.5%.
- PTS로 생성한 데이터를 학습하면서 모델이 더 많은 질문에 정확하게 답변.
- 비응답 비율 증가: 환각 대신 질문을 시도하지 않는 응답이 증가.
- 모델이 확실하지 않은 경우 오답을 생성하지 않고 응답을 회피하도록 학습됨.
- 오답 비율 감소: 약 10% 미만.
- 정답 비율 증가: 약 57.5%.
- DPO 2단계:
- 정답 비율 최종 증가: 약 81.1%.
- Judge-Guided 평가로 학습 데이터를 정제하면서 정답률이 대폭 상승.
- 비응답 비율 약간 감소: 비응답 비율이 감소하면서 모델의 자신감이 높아짐.
- 오답 비율 최소화: 약 3.0%로 낮아짐.
- 정답 비율 최종 증가: 약 81.1%.

- DPO(선호 최적화) 단계별 성능:
- GPQA(47.3 → 56.1), MATH(77.1 → 80.4) 등에서 지속적인 성능 향상.
- 특징: 첫 번째 DPO(피보탈 토큰 기반)는 추론 강화에 효과적이고, 두 번째 DPO(판단 기반)는 스타일 및 표현에 강점.
QA
#backbone model은 뭐냐
Phi-4는 Phi-3-medium을 기반으로 함
Phi-3의 아키텍처는 llama 2의 아키텍처를 따름
#4k → 16k 변경 이유
긴 문맥이 필요한 작업(예: 긴 문서 요약, 코드 분석, 대규모 데이터셋 질의)을 처리하기 위해 컨텍스트 길이의 확장이 필요했음
긴 문맥을 처리하기 위한 모델 구조와 데이터는 초기 학습에서 매우 불안정하게 작동할 가능성이 높음
4K 학습에서 축적된 지식을 기반으로 16K 학습을 진행하면, 긴 문맥에서도 더 빠르고 안정적으로 학습이 가능
'공부방' 카테고리의 다른 글
| 논문 리뷰: s1: Simple test-time scaling (1) | 2025.02.18 |
|---|---|
| 논문 리뷰: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (3) | 2025.02.05 |
| 논문 리뷰: From Local to Global: A Graph RAG Approach to Query-Focused Summarization (0) | 2024.12.23 |
| WSL 환경 localhost는 통신이 되지만, Host IP는 통신이 안되는 현상 (1) | 2024.12.18 |
| FastAPI : 파일 처리 (3) | 2024.09.09 |
'공부방' Related Articles
more



