
Notice
Recent Posts
Recent Comments
Link
헬창 개발자
판다스 매트플롯 다루기 본문
이 페이지의 목적
- Pandas 기본 사용법 이해
- Matplotlib 기본 사용법 이해
Pandas
◾데이터 읽기
- import : 모듈을 사용하기 위한 명령
- import Module : 모듈을 사용하겠다.
- import Module as md : 모듈을 사용할 때 md라는 이름으로 사용하겠다.
- from Module import function : 모듈에 포함된 function이라는 함수만 사용하겠다.
- pandas 사용
- 파이썬의 강력한 분석 툴킷
- 단일 프로세스에서 최대 효율
- pandas는 통상 pd로 import
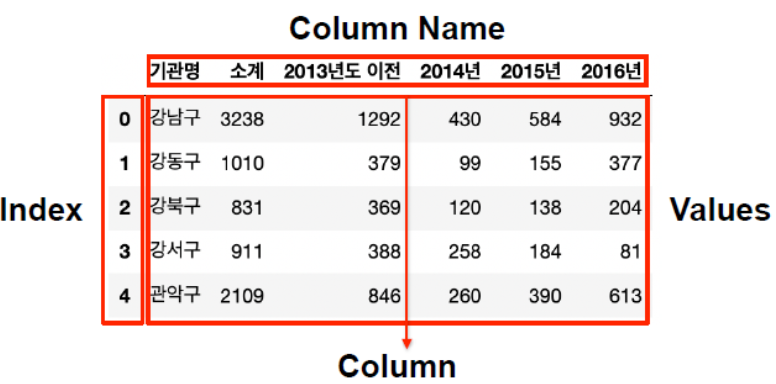
- pandas DataFrame 구조 - index : 행, column : 열, value : 값
1. CSV 읽기
- read_csv : csv 파일을 읽는 명령
- 한글이 포함되어 있을 경우 encoding='utf-8' 옵션을 사용
import pandas as pd
# .. : 부모 디렉터리
# . : 현재 디렉터리
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")
# 데이터의 상위 5개 데이터
# 데이터의 개수를 입력하여 원하는 만큼 볼 수 있다.
CCTV_Seoul.head()
# 데이터의 하위 5개 데이터
# 데이터의 개수를 입력하여 원하는 만큼 볼 수 있다.
# CCTV_Seoul.tail()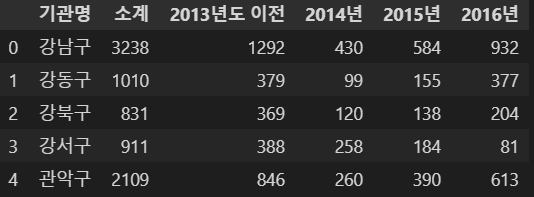
- 컬럼 이름 조회 : columns, columns[인덱스]
- 컬럼 이름 변경 : rename(columns={컬럼 : 변경할 이름}
- inplace 옵션 : 작업을 진행한 데이터를 새 데이터로 반환할 지 현재 데이터에 적용할지 설정
- False : 작업한 데이터 반환
- True : 작업한 데이터 현재 데이터에 적용
# 컬럼명 확인
CCTV_Seoul.columns
CCTV_Seoul.columns[0]
# 컬럼명 변경
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0] : "구별"}, inplace=True)2. 엑셀 읽기
- read_excel : 엑셀 파일을 읽는 명령
pop_Seoul = pd.read_excel("../data/01. Seoul_Population.xls")
pop_Seoul.head()
- 원하지 않는 행이 출력되므로 옵션을 통해 설정한다.
- header : 시작할 행 지정
- usecols : 읽어올 컬럼 지정(엑셀의 컬럼은 A,B,C,D,.. 등 영어로 이루어져있다.)
# 헤더와 사용할 컬럼 지정('계' 컬럼들만 사용)
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)
pop_Seoul.head()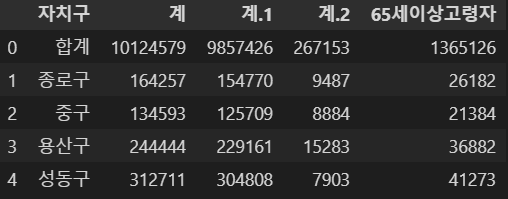
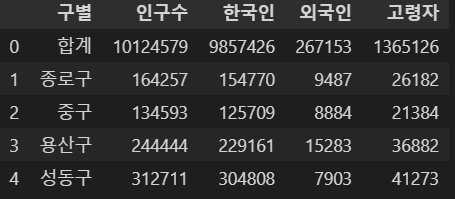
- 컬럼 이름을 알아보기 쉽게 변경
pop_Seoul.rename(
columns={
pop_Seoul.columns[0] : "구별",
pop_Seoul.columns[1] : "인구수",
pop_Seoul.columns[2] : "한국인",
pop_Seoul.columns[3] : "외국인",
pop_Seoul.columns[4] : "고령자",
},
inplace=True,
)
◾Pandas 기초
- pandas 통상 pd로, 수치해석적 함수가 많은 numpy는 np로 import
import pandas as pd
import numpy as np1. Series()
- Pandas 데이터형을 구성하는 기본 자료형
- index와 value로 구성
- 계산을 위해 한 가지 데이터 타입이 좋다
- 딕셔너리로 인덱스 값을 지정할 수 있다.
s = pd.Series([1, 3, 5, np.nan, 6, 8])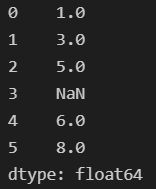
# 딕셔너리
pd.Series({"Key":"Value"})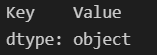
2. date_range()
- 날짜(시간)을 사용할 수 있다.
dates = pd.date_range('20130101', periods=6)
3. DataFrame()
- Pandas에서 가장 많이 사용되는 데이터형
- index, column, value로 구성
- 각 컬럼은 Series로 구성
- 난수를 생성해 DataFrame 생성
data = np.random.randn(6, 4)
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])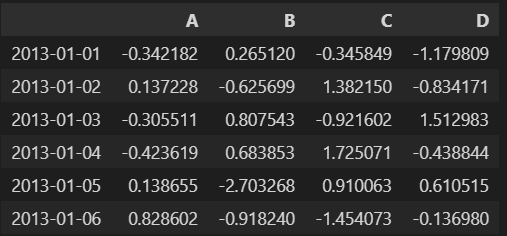
- df의 index, columns, values 조회
df.index
df.columns
df. values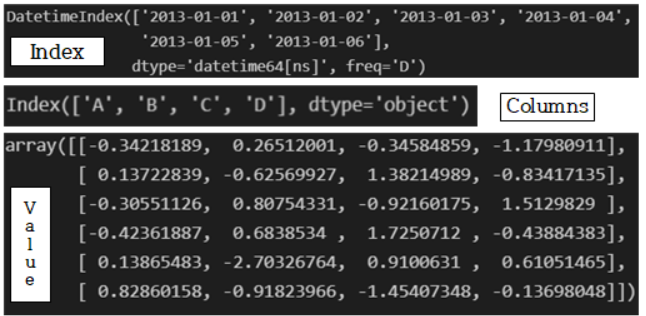
- describe : DataFrame의 기술통계 정보
- df.describe()
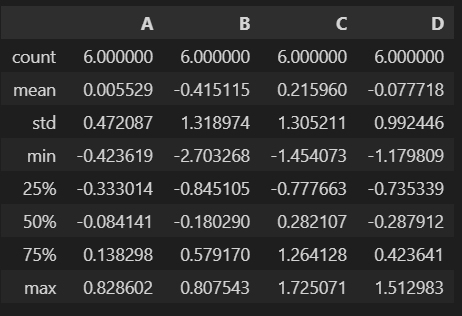
- df.describe()
- 데이터 정렬 : sort_values(by=컬럼, ascending=Bool)
- ascending = True : 오름차순
- ascending = False : 내림차순
df.sort_values(by="B", ascending=False)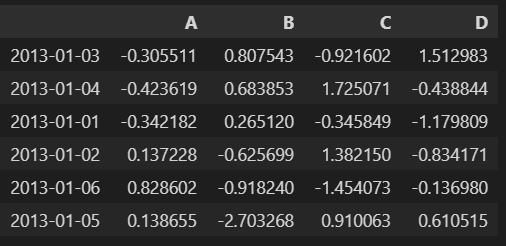
- 컬럼 읽기 : df["컬럼"]
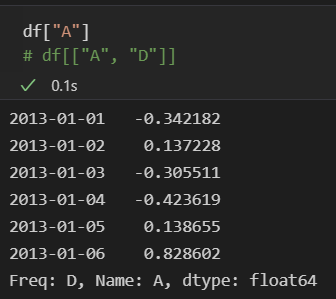
◾Pandas Slice
- 특정 행 읽기 :df[n:m]
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우 끝을 포함
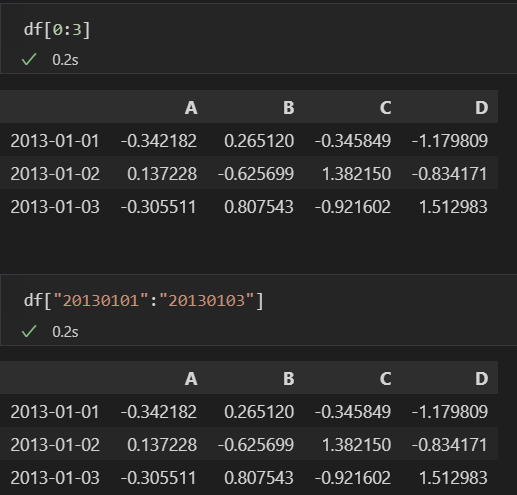
- loc[행, 열] : location
- index명, column명을 이용해 행과 열을 선택하는 함수
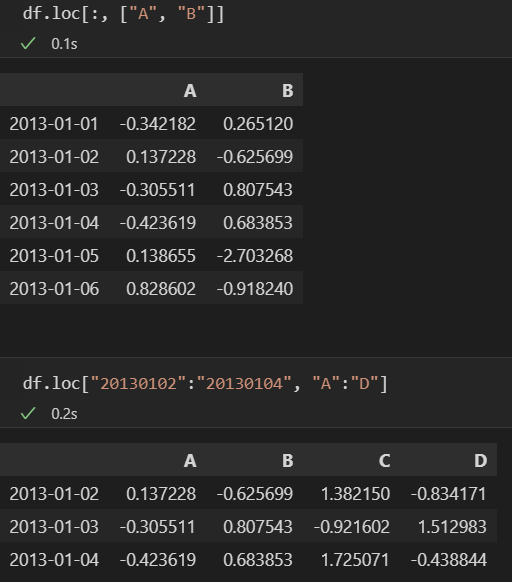
- index명, column명을 이용해 행과 열을 선택하는 함수
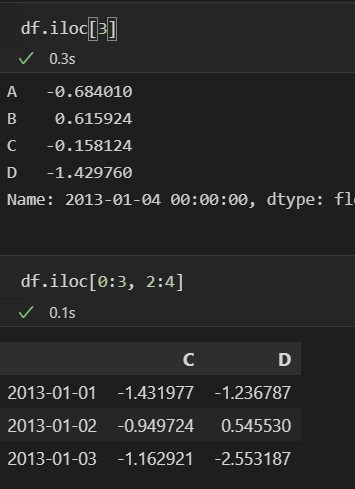
- iloc[행, 열] : index명, column명 대신 인덱스를 활용하여 행과 열을 선택하는 함수
◾Pandas Condition
- 조건을 통해 원하는 값을 출력하는 것이 일반적 : df[조건]
- NaN : Not a Number
- A 컬럼의 값이 0 초과인 경우
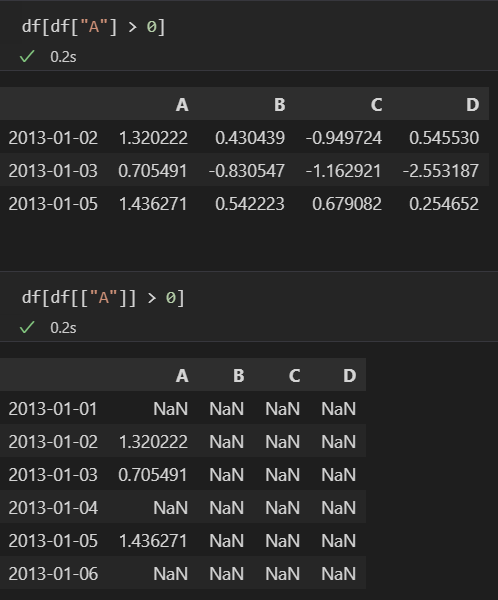
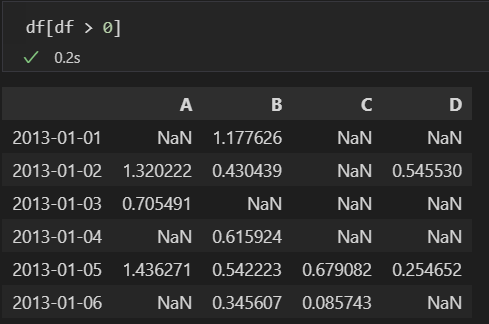
- 전체 값중 0 초과인 경우
- 컬럼값 추가 : df[컬럼명]=[값]
- 기존 컬럼이 없으면 추가하고 있다면 변경
- isin() : 특정 요소가 있는지 확인
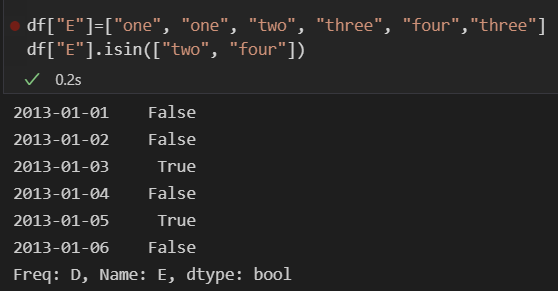
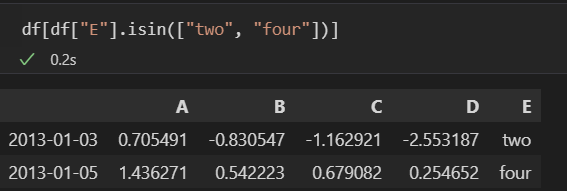
◾Pandas Remove
- del df["컬럼"] : 컬럼 삭제
- drop("컬럼 또는 인덱스", axis = 값) : axis 값에 따라 행 또는 열 삭제
- axis = 0 : 가로
- axis = 1 : 세로
- 기본 axis는 0
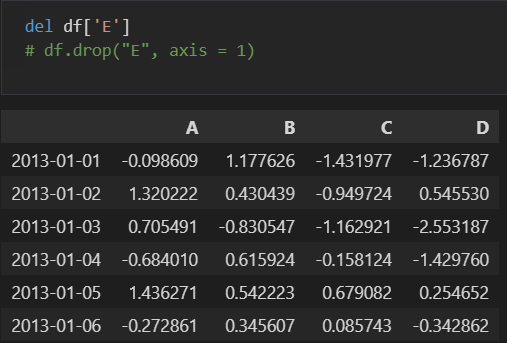
◾Pandas Apply Function
- apply() : 원하는 계산 수행
- sum : 합, mean : 평균, min : 최소값, max : 최대값
- numpy의 기능도 사용 가능

- apply(np.cumsum) : 각 컬럼 값 누적합
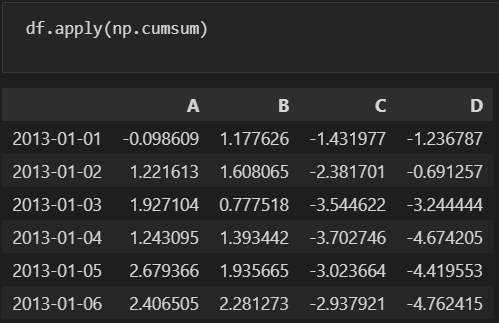
◾데이터 병합
1. 데이터 병합 기초
- pd.concat()
- pd.join()
- pd.merge()
- merge를 이용해 데이터 병합
- DataFrame끼리 병합이 빈번하므로 꼬이지않게 주의
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 병합
- 기준이 되는 컬럼이나 인덱스를 키라고 한다
- 기준이 되는 키 값은 두 데이터 프레임에 모두 포함되어 있어야한다.
- 테스트 데이터
left = pd.DataFrame(
{
"Key" : ["K0", "K4", "K2", "K3"],
"A" : ["A0","A1","A2","A3"],
"B" : ["B0","B1","B2","B3"]
}
)
right = pd.DataFrame([
{"Key":"K0", "C":"C0", "D":"D0"},
{"Key":"K1", "C":"C1", "D":"D1"},
{"Key":"K2", "C":"C2", "D":"D2"},
{"Key":"K3", "C":"C3", "D":"D3"},
])- merge(df1, df2, on = '컬럼') : df1, df2를 '컬럼'을 기준으로 병합
- on의 칼럼을 기준으로 공통된 값을 가지는 경우만 병합
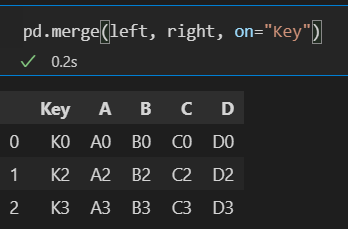
- on의 칼럼을 기준으로 공통된 값을 가지는 경우만 병합
- merge(df1, df2, how="df1", on = '컬럼')
- how의 df1에 on의 컬럼을 기준으로 df2 병합
- df2의 값이 없는 경우 NaN을 추가
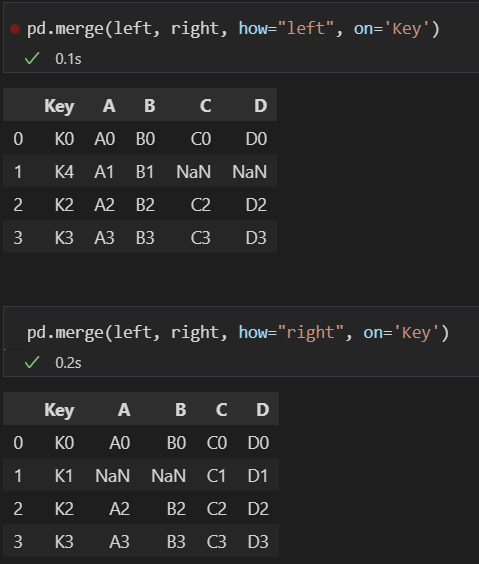
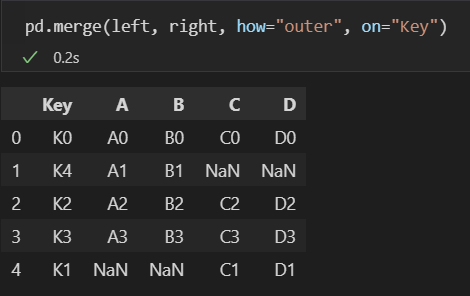
- merge(df1, df2, how="outer", on = '컬럼')
- df1, df2의 모든 데이터를 on의 컬럼을 기준으로 병합
- 값이 없는 경우 NaN을 추가
- merge(df1, df2, how="inner", on = '컬럼')
- 기본적인 동작과 동일하게 값이 두 df에 있는 경우만 병합
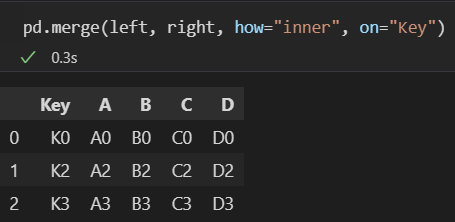
- 기본적인 동작과 동일하게 값이 두 df에 있는 경우만 병합
Matplotlib
- 파이썬의 대표 시각화 도구
- import matplotlib.pyplot as plt 로 많이 사용
- Juypter NoteBook의 경우 결과가 out session에 나타난다.
- %matplotlib inline 옵션을 사용 : 결과창을 새 창에 열지 않고 현재 Jupyter Notebook 창에 출력
import pandas as pd
# matlab의 기능을 담아둔 것이 pyplot
import matplotlib.pyplot as plt
%matplotlib inline
# get_ipython().run_line_magic("matplotlib", "inline")- matplotlib 기본 형태
- plt.figure() : 그래프에 대한 속성 설정
- plt.plot([가로축], [세로축]) : 세로축, 가로축의 데이터 설정
- plt.show() : 결과 출력
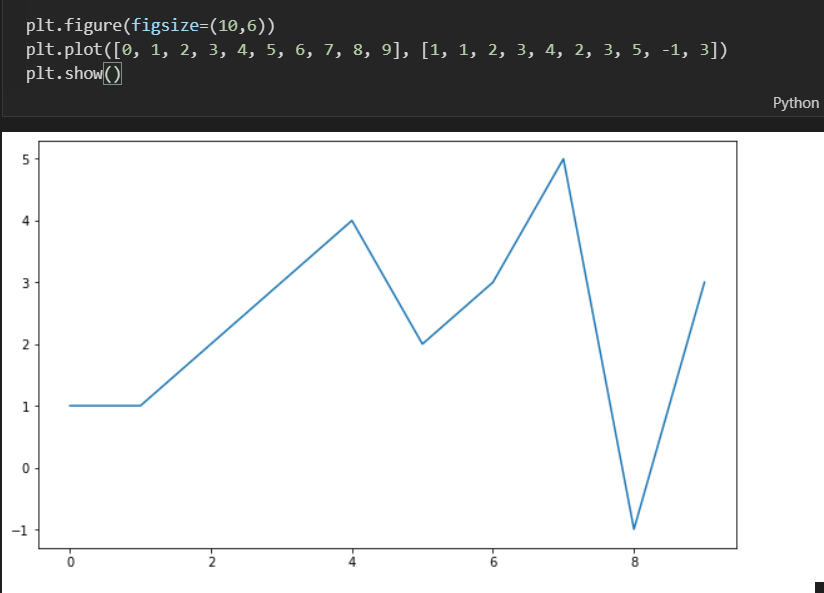
- 삼각함수 그리기
- numpy의 sin() 사용
- np.arange(a,b,s) : a부터 b까지의 s간격의 데이터
- np.sin(value) : 사인 함수
- numpy의 sin() 사용
import numpy as np
t = np.arange(0, 12, 0.01)
def drawGraph():
plt.figure(figsize=(10, 6))
# label : 해당 그래프의 이름
plt.plot(t, np.sin(t), label='sin')
plt.plot(t, np.cos(t), label="cos")
# grid : 그래프에 격자 표시
plt.grid()
# legend : plot의 label 표시
plt.legend(loc="upper right")
# xlabel : x축의 제목
plt.xlabel("time")
# ylabel : y축의 제목
plt.ylabel("Amplitude")
# title : 전체 그래프의 제목
plt.title("Example of sinewave")
plt.show()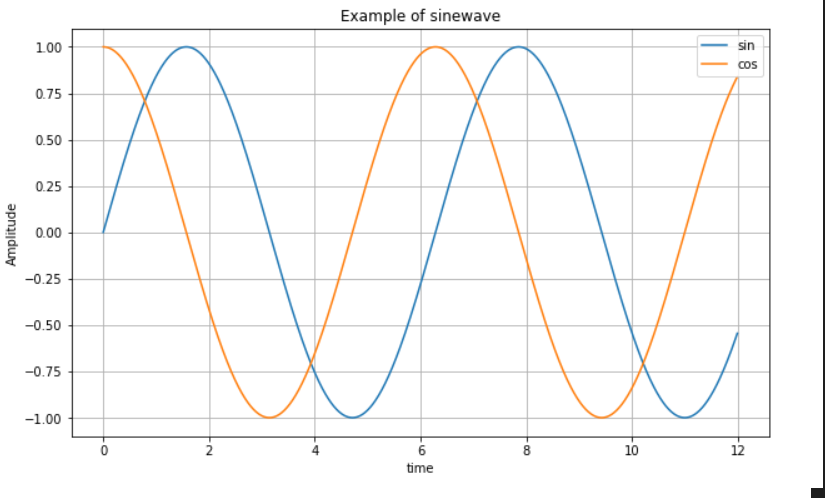
- 추가 실습
t = np.arange(0, 5, 0.5)
def drawGraph():
plt.figure(figsize=(10,6))
# r-- : r은 빨간색, --은 점선
plt.plot(t, t, "r--")
# bs : b는 파랑색, s는 사각형
plt.plot(t, t ** 2, "bs")
# g^ : g는 초록색, ^는 위 방향 화살표
plt.plot(t, t ** 3, "g^")
plt.show()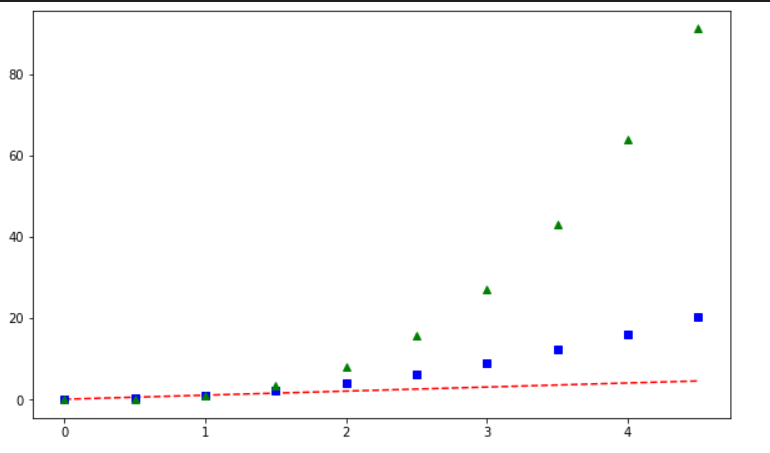
- 다양한 스타일 지정
t = [0, 1, 2, 3, 4, 5, 6]
y = [1, 4, 5, 8, 9, 5, 3]
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(
# x축
t,
# y축
y,
# 그래프 색상
color = "green",
# 그래프 스타일
linestyle="dashed",
# 마커 스타일
marker="o",
# 마커 색상
markerfacecolor="blue",
# 마커 사이즈
markersize=12,
)
# x축과 y축의 범위 지정
plt.xlim([-0.5, 6.5])
plt.ylim([0.5,9.5])
plt.show()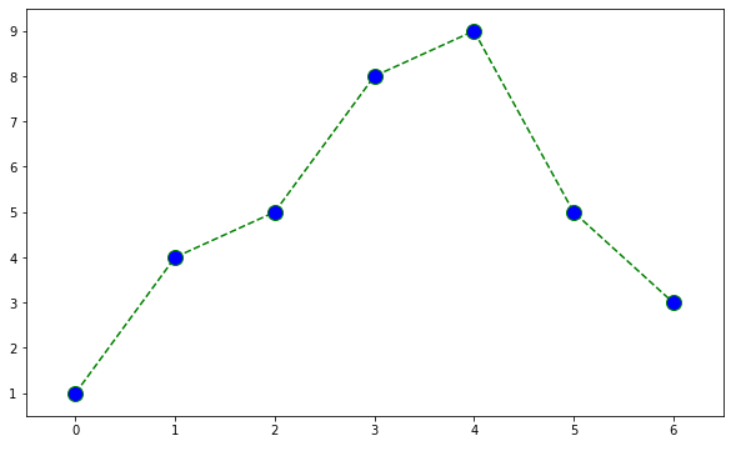
- scatter() : 점 그래프
# scatter는 점을 뿌리듯이 그리는 그래프
t = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([9, 8, 7, 9, 8, 3, 2, 4, 3, 4])
def drawGraph():
plt.figure(figsize=(10, 6))
plt.scatter(t, y)
plt.show()
- colormap : 값에 따라 색상 다르게 적용
colormap = t
def drawGraph():
plt.figure(figsize=(10, 6))
# marker : 점의 모양
plt.scatter(t, y, s=50, c=colormap, marker=">")
# colormap의 색상을 막대 그래프로 출력
plt.colorbar()
plt.show()
'데이터 분석' 카테고리의 다른 글
| 2. 서울시 범죄 현황 분석 (0) | 2022.02.15 |
|---|---|
| 카카오 API, Folium 다루기 (0) | 2022.02.15 |
| 1. 서울시 cctv 현황 분석 (0) | 2022.02.15 |
| 환경 설정 (0) | 2022.02.15 |
| 카카오 지도 API 발급 받는 방법 (0) | 2022.01.16 |
'데이터 분석' Related Articles
more




Comments