
Notice
Recent Posts
Recent Comments
Link
헬창 개발자
2. 서울시 범죄 현황 분석 본문
학습 목표
- 카카오 맵 api 사용법 이해
- 시각화 라이브러리 이해
1. 개요
- 데이터 과학의 목적
- 가정(혹은 인식)을 검증하고 표현하는 것
- 2014-10월 기사 : 서울 강남 3구 체감안전도 높아 => 검증 및 확인 https://www.news1.kr/articles/?1911504
- 활용 :
Googlemaps, Kakaomaps, Folium, Matplotlib, Seaborn, Pandas, Numpy
- 데이터 얻기
- 서울시 관서별 5대 범죄 현황
- Github 자료 사용
- 서울시 관서별 5대 범죄 현황
- 데이터 읽기
- numpy, pandas 사용
- thousands 옵션 : 숫자의 천단위 구분자를 제거하고 숫자형으로 읽는 설정
- 숫자에 구분자가 있는 경우 문자로 인식하기 때문에 thousands 옵션 사용
2. 지오코딩
- 지오코딩이란? 지오코딩(Geocoding)은 고유명칭(주소나 산,호수의 이름등)을 가지고 위도와 경도의 좌표값를 얻는 것을 말한다.
<데이터 설명>
- 서울시 관서별 5대 범죄 발생 검거 현황 데이터: "02. crime_in_Seoul.csv" 서울시 경찰서 별로 살인, 강도, 강간, 절도, 폭력이라는 5대 범죄에 대한 발생 건수 및 검거 건수관서명: 중부서, 종로서, 남대문서, ... 살인 발생: 살인 사건 발생 건수 살인 검거: 살인 용의자 검거 건수 강도 발생: 강도 사건 발생 건수 강도 검거: 강도 용의자 검거 건수 강간 발생: 강간 사건 발생 건수 강간 검거: 강간 용의자 검거 건수 절도 발생: 절도 사건 발생 건수 절도 검거: 절도 용의자 검거 건수 폭력 발생: 폭력 사건 발생 건수 폭력 검거: 폭력 용의자 검거 건수
- 데이터 불러오기
crime_anal_police = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands=',',
encoding='euc-kr')
crime_anal_police.head()
서울시에는 한 구에 하나 또는 두 군데의 경찰서가 위치하고 있으며, 구 이름과 다른 경찰서도 존재한다. 경찰서 목록을 소속 구별로 변경해주어야 할 것 같다.
- 카카오 API 사용
import json
import requests
class KakaoLocalAPI:
"""
Kakao Local API 컨트롤러
"""
def __init__(self, rest_api_key):
# REST API 키 설정
self.rest_api_key = rest_api_key
self.headers = {"Authorization": "KakaoAK {}".format(rest_api_key)}
self.URL_05 = "https://dapi.kakao.com/v2/local/search/keyword.json"
def search_keyword(self,query,category_group_code=None,x=None,y=None,radius=None,rect=None,page=None,size=None,sort=None):
params = {"query": f"{query}"}
if category_group_code != None:
params['category_group_code'] = f"{category_group_code}"
if x != None:
params['x'] = f"{x}"
if y != None:
params['y'] = f"{y}"
if radius != None:
params['radius'] = f"{radius}"
if rect != None:
params['rect'] = f"{rect}"
if page != None:
params['page'] = f"{page}"
if size != None:
params['size'] = f"{params}"
if sort != None:
params['sort'] = f"{sort}"
res = requests.get(self.URL_05, headers=self.headers, params=params)
document = json.loads(res.text)
return document
rest_api_key = "카카오api키입력"
kakao = KakaoLocalAPI(rest_api_key)
station_name = []
station_addreess = []
station_lat = []
station_lng = []
for name in crime_anal_police['관서명']:
station_name.append('서울' + str(name[:-1]) + '경찰서')
for name in station_name:
a = kakao.search_keyword(name)
tmp=a.get('documents')
station_addreess.append(tmp[0].get('road_address_name'))
station_lat.append(tmp[0].get('y'))
station_lng.append(tmp[0].get('x'))
print(name + '-->' + tmp[0].get('road_address_name'))
- 결과값 확인
print(tmp[0])
3. 데이터 정제
- 범죄 현황 데이터 불러오기
crime_anal_raw = pd.read_csv('../data/02. crime_in_Seoul_include_gu_name.csv',
encoding='utf-8')
crime_anal_raw.head()
- pivot_table을 사용해서 원 데이터를 '관서별'에서 '구별'로 변경
crime_anal_raw = pd.read_csv('../data/02. crime_in_Seoul_include_gu_name.csv',
encoding='utf-8', index_col=0)
#index_col 인덱스 지정
crime_anal = pd.pivot_table(crime_anal_raw, index='구별', aggfunc=np.sum)
#aggfunc 옵션에 np.sum 을 사용해서 '평균치'가 아닌 '합계'를 출력하도록 지정
crime_anal.head()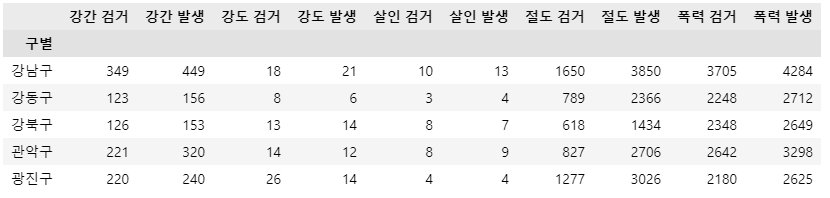
- 각 범죄별 검거율을 계산
crime_anal['강간검거율'] = crime_anal['강간 검거']/crime_anal['강간 발생']*100
crime_anal['강도검거율'] = crime_anal['강도 검거']/crime_anal['강도 발생']*100
crime_anal['살인검거율'] = crime_anal['살인 검거']/crime_anal['살인 발생']*100
crime_anal['절도검거율'] = crime_anal['절도 검거']/crime_anal['절도 발생']*100
crime_anal['폭력검거율'] = crime_anal['폭력 검거']/crime_anal['폭력 발생']*100
#검거 건수는 검거율로 대체할 수 있기 때문에 삭제
del crime_anal['강간 검거']
del crime_anal['강도 검거']
del crime_anal['살인 검거']
del crime_anal['절도 검거']
del crime_anal['폭력 검거']
con_list = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
# 검거율이 100이 넘는 숫자들은 모두 100으로 처리
for column in con_list:
crime_anal.loc[crime_anal[column] > 100, column] = 100
#'강간 발생', '강도 발생', ... , '폭력 발생'의 변수명을 변경
crime_anal.rename(columns = {'강간 발생':'강간',
'강도 발생':'강도',
'살인 발생':'살인',
'절도 발생':'절도',
'폭력 발생':'폭력'}, inplace=True)
crime_anal.head()
- 데이터 표현을 위해 다듬기 "정규화" '강도', '살인' 사건은 두 자릿수인데, '절도'와 '폭력'은 네 자릿수이다. 각각을 비슷한 범위에 놓고 비교하는 것이 편리하기 때문에, 데이터를 좀 다듬어주자
- 각 항목의 최댓값을 '1'로 두면, 추후 범죄 발생 건수를 종합적으로 비교할 때 편리할 것이다!
- 즉, 강간, 강도, 살인, 절도, 폭력에 대해 각 컬럼 별로 '정규화' 처리를 수행하였다
- 사이킷런의 최솟값, 최댓값을 이용해서 정규화시키는 MinMaxScaler() 함수 사용
==> '정규화'처리된 데이터를 살펴보면 '구별'로 '강간', '강도', '살인', '절도', '폭력' 변수의 값들이 0 ~ 1 사이의 값으로 변경되었음을 확인할 수 있다.
from sklearn import preprocessing
col = ['강간', '강도', '살인', '절도', '폭력']
x = crime_anal[col].values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x.astype(float))
crime_anal_norm = pd.DataFrame(x_scaled, columns = col, index = crime_anal.index)
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal[col2]
crime_anal_norm.head()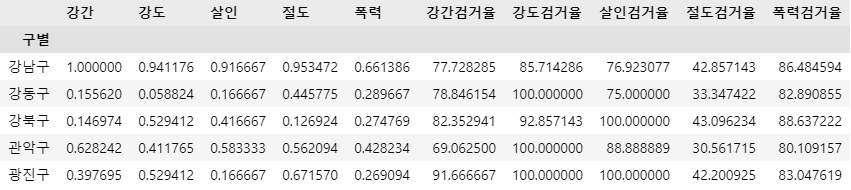
- 1장에서 만들어 놓은 "01. CCTV_result.csv" 파일에서 필요한 변수들만 추출
result_CCTV = pd.read_csv('../data/01. CCTV_result.csv', encoding='UTF-8',
index_col='구별')
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]
#각 범죄 발생 건수의 합을 '범죄'라는 항목으로 통합!
col = ['강간','강도','살인','절도','폭력']
crime_anal_norm['범죄'] = np.sum(crime_anal_norm[col], axis=1)
#각 범죄별 검거율의 합을 '검거'라는 항목으로 통합!
col = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
crime_anal_norm['검거'] = np.sum(crime_anal_norm[col], axis=1)
crime_anal_norm.head()
4. 범죄 현황 데이터 시각화
- SeabornMatplotlib과 함꼐 사용하는 시각화 도구 seaborn을 import할 때는 matplotlib도 같이 import 되어 있어야 한다.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import platform
#한글 폰트 문제를 해결
path = "c:/Windows/Fonts/malgun.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')- pairplot을 사용한 상관관계 확인
sns.pairplot(crime_anal_norm, x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"], kind='reg', size=3)
plt.show()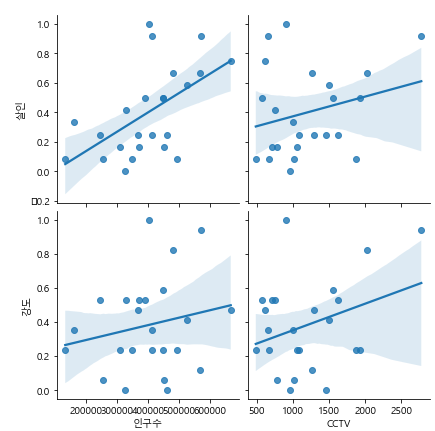
"인구수"와 "살인"의 상관계수가 제일 높아보인다. 즉, 인구가 많은 곳이 살인이 비교적 많이 일어난다고 할 수 있겠다.
sns.pairplot(crime_anal_norm, x_vars=["인구수", "CCTV"],
y_vars=["살인검거율", "폭력검거율"], kind='reg', size=3)
plt.show()
sns.pairplot(crime_anal_norm, x_vars=["인구수", "CCTV"],
y_vars=["절도검거율", "강도검거율"], kind='reg', size=3)
plt.show()
대부분 음의 상관관계가 있는 것으로 나왔다.
CCTV가 많이 설치되어 있다고 해서, 검거율이 높은 건 아닌 듯 싶다.
- 발생 건수, 비율로 정렬해서 heatmap으로 시각화
tmp_max = crime_anal_norm['검거'].max()
crime_anal_norm['검거'] = crime_anal_norm['검거'] / tmp_max * 100
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
target_col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
plt.figure(figsize = (10,10))
sns.heatmap(crime_anal_norm_sort[target_col], annot=True, fmt='f',
linewidths=.5, cmap='RdPu')
plt.title('범죄 검거 비율 (정규화된 검거의 합으로 정렬)')
plt.show()
#############################################################
target_col = ['강간', '강도', '살인', '절도', '폭력', '범죄']
crime_anal_norm['범죄'] = crime_anal_norm['범죄'] / 5
crime_anal_norm_sort = crime_anal_norm.sort_values(by='범죄', ascending=False)
plt.figure(figsize = (10,10))
sns.heatmap(crime_anal_norm_sort[target_col], annot=True, fmt='f', linewidths=.5,
cmap='RdPu')
plt.title('범죄비율 (정규화된 발생 건수로 정렬)')
plt.show()
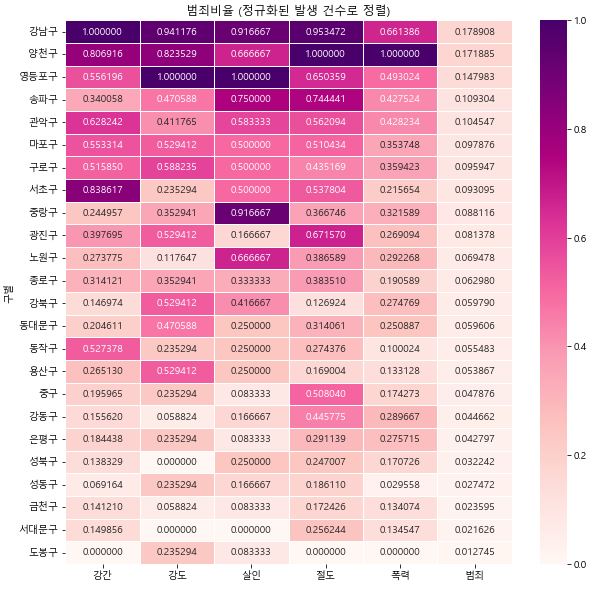
- 발생 건수로 봤을 때는 강남구, 양천구, 영등포구 가 범죄 발생 건수가 높다.
- 또한 강남 3구인 송파구 와 서초구 도 범죄 발생 건수가 낮다고는 할 수 없어보인다.
- 이러한 결과로 보았을 때, 과연 강남 3구가 범죄로부터 안전하다고 할 수 있을까??
4. 범죄 현황 지도 시각화
- Folium
- Folium 은 시각화 도구이다.
- Folium 라이브러리를 사용하려면, cmd 창을 켜고 pip install folium 이라는 명령문을 입력해서 설치해야 한다.
- skorea_municipalities_geo_simple.json
{"type":"FeatureCollection","features":[ {"type":"Feature", "id":"강동구", "properties":{"code":"11250", "name":"강동구", "name_eng":"Gangdong-gu", "base_year":"2013"}, "geometry":{"type":"Polygon","coordinates": [[[127.11519584981606,37.557533180704915], [127.16683184366129,37.57672487388627], [127.18408792330152,37.55814280369575], [127.16530984307447,37.54221851258693], [127.14672806823502,37.51415680680291], [127.12123165719615,37.52528270089], [127.1116764203608,37.540669955324965], [127.11519584981606,37.557533180704915]]]}},
- 구별 살인 현황 지도에 표현
import json
# 검거율 데이터
crime_anal_norm=pd.read_csv('../data/02. crime_in_Seoul_final.csv', encoding='utf-8')
# 지도 데이터
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
map = folium.Map(location=[37.5502, 126.982], zoom_start=11,
tiles='Stamen Toner')
map.choropleth(geo_data = geo_str,
#colormap 은 살인 발생 건수('살인')로 지정
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['살인']],
fill_color = 'PuRd', #PuRd, YlGnBu
key_on = 'feature.id')
map
- 구별 범죄 현황과 경찰서별 검거율 지도에 표현
crime_anal_raw['lat'] = station_lat
crime_anal_raw['lng'] = station_lng
col = ['살인 검거', '강도 검거', '강간 검거', '절도 검거', '폭력 검거']
# 각 범죄별 검거 건수를 해당 범죄의 최대 검거 건수로 나눠준다
tmp = crime_anal_raw[col] / crime_anal_raw[col].max()
# axis = 1 로 설정해서, 각 경찰서별로 검거율을 합해준다
crime_anal_raw['검거'] = np.sum(tmp, axis=1)
map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
map.choropleth(geo_data = geo_str,
data = crime_anal_norm['범죄'],
columns = [crime_anal_norm.index, crime_anal_norm['범죄']],
fill_color = 'PuRd', #PuRd, YlGnBu
key_on = 'feature.id')
# 각 경찰서의 위도 및 경도 정보를 이용해서, folium 으로 시각화
for n in crime_anal_raw.index:
folium.CircleMarker([crime_anal_raw['lat'][n], crime_anal_raw['lng'][n]],
radius = crime_anal_raw['검거'][n]*10,
color='#3186cc', fill_color='#3186cc', fill=True).add_to(map)
map
5. 결론
<최종 시각화 결과 해석>
- 지도에서 범죄가 많이 발생할수록 붉은색이고, 원의 크기가 넓을수록 해당 경찰서의 검거율이 높다는 의미이다.
- 결과를 자세히 살펴보면, 서울 서부는 범죄가 많이 발생하지만 검거율이 비교적 높은 편이다.
- 반면, 서울 북부는 범죄 발생 건수가 적고 검거율 또한 낮다.
- 이제 우리가 증명해보려 했던 "강남 3구는 범죄로부터 정말 안전할까?"라는 가설에 대해 확인해보겠다.
- 강남 3구(강남구, 서초구, 송파구)에 각종 유흥업소들이 많이 밀집되어 있어서 범죄 발생 건수가 높은 편이다.
- 그에 비해 강남 3구의 검거율이 매우 좋아보이지는 않는다.
- 이러한 결과를 보았을 때, 과연 강남 3구가 정말로 범죄로부터 안전한지에 대한 의문이 남는다.
'데이터 분석' 카테고리의 다른 글
| Selenium 기초 (0) | 2022.02.15 |
|---|---|
| 3. 네이버 영화 평점 크롤링 (5) | 2022.02.15 |
| 카카오 API, Folium 다루기 (0) | 2022.02.15 |
| 판다스 매트플롯 다루기 (0) | 2022.02.15 |
| 1. 서울시 cctv 현황 분석 (0) | 2022.02.15 |
'데이터 분석' Related Articles
more



