
Notice
Recent Posts
Recent Comments
Link
헬창 개발자
3. 네이버 영화 평점 크롤링 본문
학습 목표
- Beautiful Soup 모듈 이해
0. 들어가기 전
- 크롤링(Crawling)이란?
웹 인덱싱을 위해 WWW를 체계적으로 탐색해나가는 것을 의미합니다. 크롤러가 하는 행위(WWW를 탐색해나가는 행위 등)를 바로 ‘크롤링’ 이라고 합니다.
1. 데이터 확인
- 사용 모듈
import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib import rc %matplotlib inline plt.rcParams["axes.unicode_minus"] = False rc('font', family='Malgun Gothic') from bs4 import BeautifulSoup from urllib.request import urlopen from tqdm import notebook - BeautifulSoup
HTML정보로 부터 원하는 데이터를 가져오기 쉽게 비슷한 분류의 데이터별로 나누어주는 파이썬 라이브러리
- urlopen
해당 URL을 열고 데이터를 얻을 수 있는 함수와 클래스 제공하며, HTTP 를 통해 웹 서버에 데이터를 얻는 데 많이 사용된다.
- notebook
진행상태 표시
from tqdm.notebook import tqdm import time for i in tqdm(range(10)): print(i) time.sleep(0.5)
- BeautifulSoup 테스트
url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20220214" page = urlopen(url) soup = BeautifulSoup(page, "html.parser") print(soup.prettify())

개발자 모드로 태그 확인하기
크롬으로 접속 후 F12
• https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20220214
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com
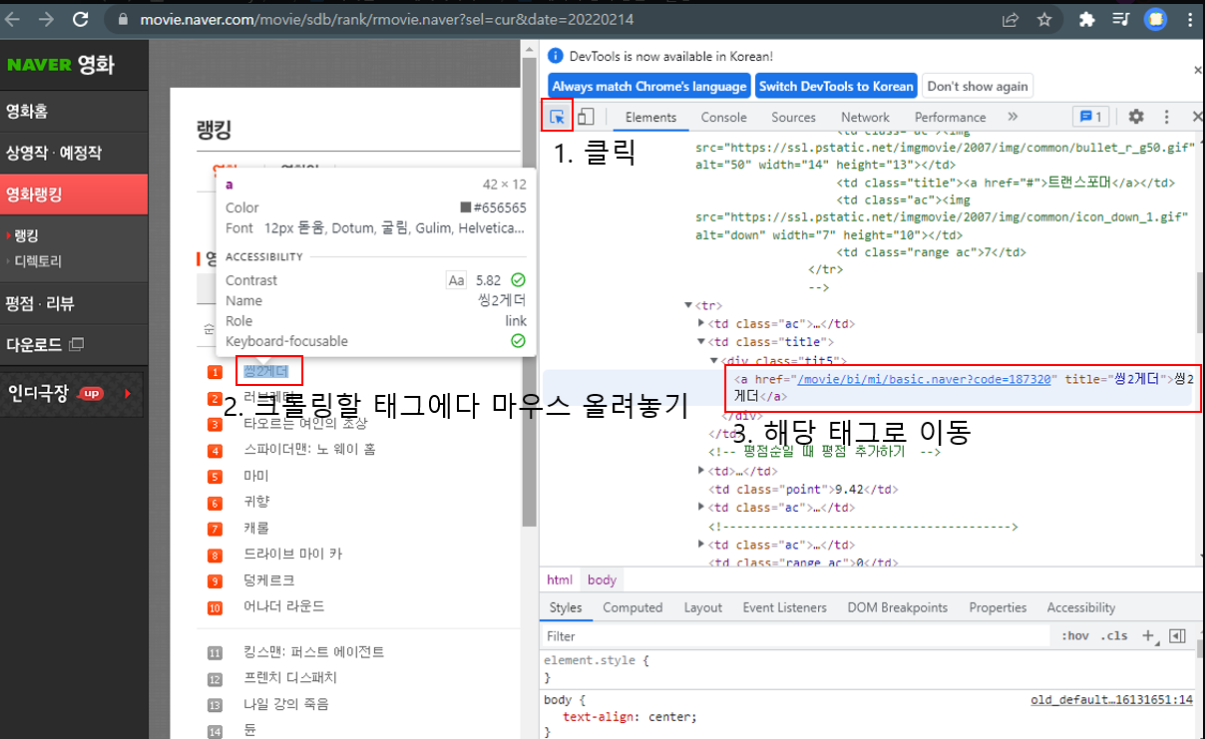
- 영화 제목 : <td class = "title"> <a href="" title=""></a> <div class = "tit5">
- 영화 평점 : <td class = "point"> </td>
2. 데이터 분석
- html 태그를 이용한 크롤링
len(soup.find_all("div", class_="tit5")) soup.find_all("div", class_="tit5")[:5]
- 제목, 평점 크롤링
# 영화 제목 리스트 end = len(soup.find_all('div', class_='tit5')) movie_name = [soup.find_all('div', class_='tit5')[n].a.string for n in range(0, end)] # 영화 평점 리스트 end = len(soup.find_all('td', class_='point')) movie_point = [soup.find_all('td', class_='point')[n].string for n in range(0, end)] # 데이터 확인 print(movie_name[:5]) print(movie_point[:5])
3. 데이터 확보
- 일별 영화 평점 데이터 수집
date = pd.date_range("2022.01.01", periods=40, freq="D") import time movie_date = [] movie_name = [] movie_point = [] for today in notebook.tqdm(date): html = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date={day}" response = urlopen(html.format(day=today.strftime("%Y%m%d"))) soup = BeautifulSoup(response, "html.parser") end = len(soup.find_all("td", class_='point')) movie_date.extend([today for n in range(0, end)]) movie_name.extend([soup.find_all("div", class_='tit5')[n].a.string for n in range(0, end)]) movie_point.extend([soup.find_all("td", class_='point')[n].string for n in range(0, end)]) # 속도 조절을 위해 사용 time.sleep(0.5) 
- 결과 확인
movie = pd.DataFrame({ "date" : movie_date, "name" : movie_name, 'point' : movie_point} ) movie.head() 
- 데이터 변경
movie["point"] = movie["point"].astype(float) movie.info()
-
4. 데이터 정리
- pivot_table로 데이터 간소화
movie_unique = pd.pivot_table(movie, index=["name"], aggfunc=np.sum) movie_best = movie_unique.sort_values(by="point", ascending=False) movie_best.head(10)
- pivot_table로 데이터 간소화
movie_pivot = pd.pivot_table(movie, index=["date"], columns=['name'], values=['point']) movie_pivot.columns = movie_pivot.columns.droplevel() movie_pivot.head()
- pivot_table로 데이터 간소화
-
4. 데이터 시각화
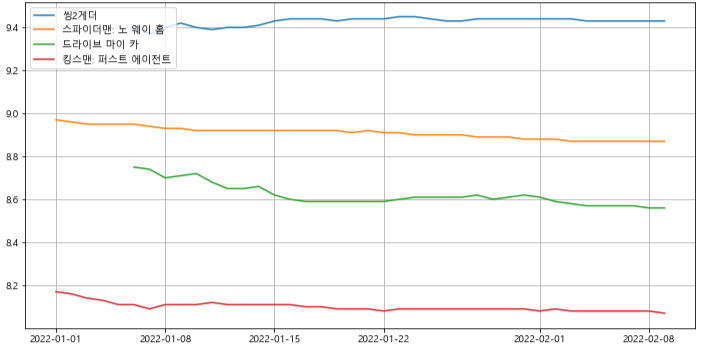
- 일별 영화 평점 시각화
target_col = ["씽2게더","스파이더맨: 노 웨이 홈","드라이브 마이 카","킹스맨: 퍼스트 에이전트"] plt.figure(figsize=(12,6)) plt.plot(movie_pivot.index, movie_pivot[target_col]) plt.legend(target_col, loc='upper left') plt.grid() plt.show()
- 일별 영화 평점 시각화
'데이터 분석' 카테고리의 다른 글
| 4. 셀프 주유소는 정말 저렴할까? (2) | 2022.02.15 |
|---|---|
| Selenium 기초 (0) | 2022.02.15 |
| 2. 서울시 범죄 현황 분석 (2) | 2022.02.15 |
| 카카오 API, Folium 다루기 (0) | 2022.02.15 |
| 판다스 매트플롯 다루기 (0) | 2022.02.15 |
'데이터 분석' Related Articles
more



